

A/B Testing is one of the most effective ways to optimize your website, improve conversions, and make data-backed decisions.
However, running an A/B test isn’t as simple as flipping a switch—mistakes along the way can distort your results, leading to misleading insights and wasted efforts.
From setting up the test to analyzing the results, every stage requires careful execution. A misstep in the planning phase can make the entire test meaningless.
Errors during execution can skew your findings. And if you don’t interpret the results correctly, you might roll out a change that does more harm than good.
In this article, we’ll break down the most common A/B testing mistakes, grouped into three categories:
Categories of A/B Testing Mistakes
- Mistakes Before Running A/B Tests – Planning and setup errors that can derail your test before it even starts.
- Mistakes During A/B Tests – Execution mistakes that interfere with data accuracy.
- Mistakes After A/B Tests – Misinterpretations and missed opportunities that prevent real learning.
Understanding and avoiding these mistakes will ensure your A/B tests provide reliable insights that drive meaningful improvements.
Mistakes to Avoid Before Running A/B Tests
Before you launch an A/B test, the groundwork you lay will determine whether your experiment delivers meaningful insights or ends up as a wasted effort.
Rushing into testing without careful preparation often leads to misleading data, incorrect conclusions, and wasted time.
Here are some of the most common mistakes businesses make before an A/B test even begins—and what you should do instead.
-
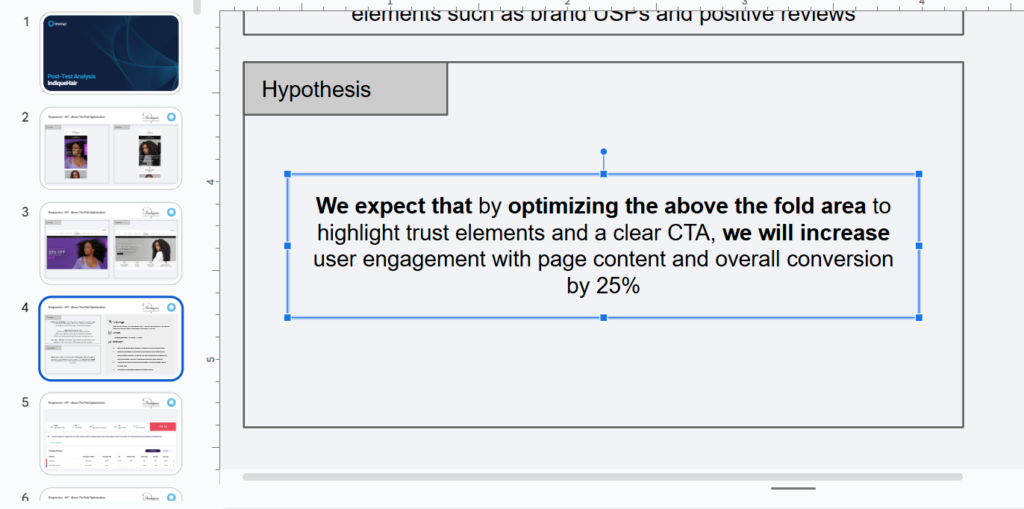
Testing Without a Clear Hypothesis
Jumping into A/B testing without a hypothesis is like setting off on a road trip with no destination. Sure, you’ll get somewhere, but will it be where you want to go?
A hypothesis is what gives your test direction. It defines what you’re trying to improve, why you think a change will work, and how you’ll measure success.
A good hypothesis answers these three questions:
- What are you changing? (e.g., changing CTA text from “Sign Up” to “Get Started”)
- Why are you changing it? (e.g., because heatmaps show users hesitate before clicking)
- What do you expect will happen? (e.g., an increase in sign-ups)

Without it, you’re just throwing variations out there and hoping for the best.
What to Do Instead:
Start by identifying a specific problem or opportunity. Then, use real data from analytics, heatmaps, or user feedback to form a clear hypothesis.
Instead of testing random changes, frame it like this: “We believe changing CTA button to color red will improve conversion because it will be more visible. We will measure success based on click-through rate.” This ensures your test is focused, measurable, and actionable.
-
Failing to Align Tests with Business Goals
One of the biggest A/B testing mistakes is running experiments without tying them to overarching business objectives. If your test focuses on improving a minor website element without considering how it impacts revenue, customer acquisition, or retention, you’re optimizing in a vacuum.
For example, if your business goal is reducing customer churn, but you’re testing button colors on the homepage, the test might improve engagement but have no meaningful effect on churn.
Without strategic alignment, you risk making changes that look good in isolation but don’t move the business forward.
How to Avoid This:
Before running any test, define how it connects to your core objectives. Ask yourself:
✔️ Does this test address a real business challenge?
✔️ Will improving this variation drive measurable progress toward a key goal (e.g., conversions, revenue, engagement)?
✔️ Is this test more valuable than other optimization opportunities?
-
Testing the Wrong Page or Feature
A/B testing takes time and resources, so choosing the wrong thing to test is a costly mistake. A minor tweak on a low-traffic page might take months to reach statistical significance while testing something inconsequential—like changing a button color on a page people rarely visit—won’t lead to impactful improvements.
What to Do Instead:
Prioritize high-impact areas. Use data to find pages or elements influencing key user actions, such as your homepage, product pages, checkout process, or lead generation forms.
If a page gets minimal traffic or doesn’t play a significant role in conversions, it’s probably not worth testing. Start with areas that will give you meaningful insights and measurable improvements.
-
Ignoring User Segmentation
Not all visitors behave the same way, yet many A/B tests treat them as one uniform group. This can be a huge oversight. New visitors and returning customers may react differently if you’re testing a change on your checkout page.
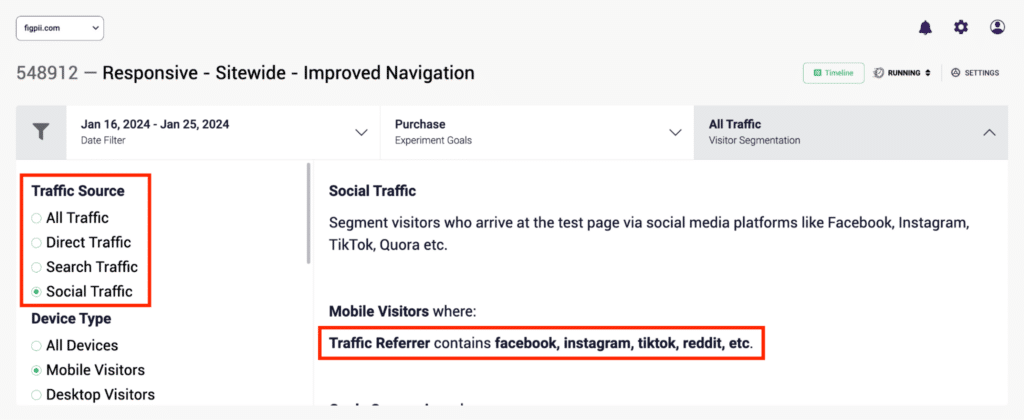
If you’re running an email test, engagement might vary based on audience segments like first-time subscribers vs. long-term customers.
If you don’t consider these differences, you could misinterpret your results and implement changes that only work for a fraction of your audience.
What to Do Instead:
Segment your audience based on relevant factors like device type, traffic source, user behavior, or demographics.
This helps you understand how different groups respond to changes. Sometimes, what works for one segment may not work for another, so adjusting your analysis accordingly ensures you’re making the right decisions for the right users.
-
Choosing the Wrong Metrics
Even if a test aligns with business goals, tracking the wrong a/b testing metrics can lead to misleading conclusions. Metrics should accurately reflect the test’s success, not just show surface-level engagement.
For instance, if you’re testing a pricing page layout, tracking page views is irrelevant—it won’t tell you if visitors actually purchased. Similarly, an A/B test on checkout design should prioritize cart completion rates, not just button clicks.
How to Avoid This:
✔️ Define a primary metric that directly measures the outcome you want (e.g., purchases, form submissions).
✔️ Choose supporting metrics to provide context (e.g., time on site, bounce rates) but don’t let them distract from the main goal.
✔️ Validate that the metric reflects user behavior changes, not just vanity improvements.
-
Not Defining a Clear Control Group
A control group is the foundation of any A/B test. It serves as the unaltered version of your webpage, email, or app experience that new variations are tested against.
If your control group isn’t properly set up, you risk drawing incorrect conclusions.
For instance, if traffic isn’t split evenly or if external variables influence the control more than the variant, your results may be skewed.
This can lead to implementing changes that don’t truly improve performance—or worse, changes that hurt your metrics.
How to Avoid This Mistake:
- Keep the control untouched: Ensure your control group remains identical throughout the test to provide a reliable comparison point.
- Ensure randomization: Distribute traffic evenly and randomly between the control and variant to prevent sampling bias.
- Use a statistically significant sample size: Running tests on too small an audience can lead to misleading results.
- Consider running an A/A test first: Before testing variations, an A/A test (comparing two identical versions) helps validate that your testing setup is reliable.
Mistakes Made During an A/B Test
-
Ignoring Mobile Traffic
A/B testing that focuses only on desktop users is like designing a restaurant menu without considering takeout customers. Mobile users interact differently; if your test ignores them, you’re only getting half the picture.
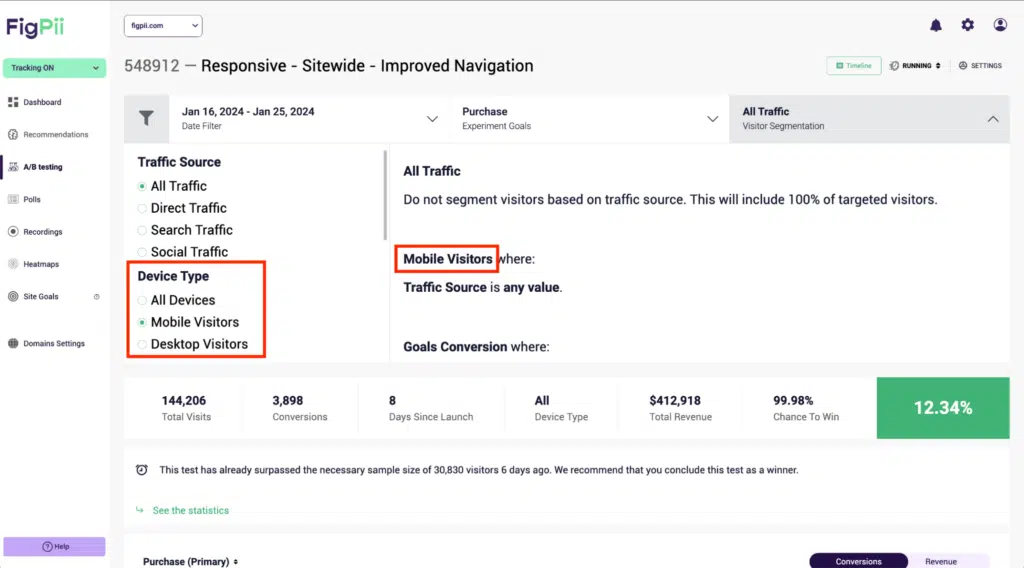
People browse differently on their phones—thumb taps instead of mouse clicks, swipes instead of scrolling, and smaller screens requiring more thoughtful layouts. The test results won’t tell you the whole story if a variation works well on a desktop but creates friction on mobile.
How to Avoid This:
✔️ Segment traffic in your A/B testing tool to separately analyze mobile vs. desktop results.
✔️ Ensure mobile responsiveness—check if variations work well across different screen sizes and devices.
✔️ Test mobile-specific elements, like button sizes, navigation menus, and page load times, to optimize for mobile behavior.
Since mobile users often make up the majority of site traffic, neglecting them can lead to misleading conclusions and missed optimization opportunities.
-
Focusing Only on Landing Pages
Landing pages often get all the attention in A/B tests, but they’re just the first step. Optimizing them without considering the full journey is like making a great store entrance but leaving the aisles cluttered.
Let’s say a test increases clicks on a landing page. That’s great, but what happens next? Do those clicks turn into purchases? Are users getting lost before checkout?
A better approach:
Broaden your scope. Test beyond the first interaction. Look at checkout pages, sign-up forms, and even post-purchase flows. Sometimes, the biggest wins happen where you least expect them.
-
Using Poor Testing Tools
The quality of your test results depends on the tool you’re using. If the platform is unreliable, your insights might be completely wrong.
Imagine running an experiment with a thermometer that gives random readings. You wouldn’t trust the results, right? The same logic applies here. Some A/B testing tools misallocate traffic, fail to track conversions properly or introduce bugs that mess with your data.
How to avoid this mess:
Don’t just pick a tool because it’s popular—verify its accuracy. Check if it tracks users correctly, integrates well with your analytics, and doesn’t mess up segmentation. If something feels off, run an A/A test first to make sure everything’s working as it should.
-
Not Reaching Statistical Significance
If you roll out a winning variation based on incomplete data, you might just be implementing a fluke. Statistical significance exists for a reason: it ensures that your results aren’t just random chance.
A business runs an A/B test, sees one version performing 15% better after three days, and immediately declares victory. But the test hasn’t gathered enough data, and a week later, the results flip.
How do you prevent this?
Use a significance threshold (95% confidence is the standard). Make sure you have a large enough sample size before calling it. A test with 100 visitors isn’t going to tell you much—run it long enough for reliable trends to emerge.
-
Not Accounting for External Factors
Say you’re testing a new checkout design, and suddenly, conversions spike. Success? Maybe. But what if a holiday sale or a viral social media post drove the increase instead of the variation?
This is where many A/B tests go wrong—they don’t factor in external influences. Seasonality, marketing campaigns, and industry trends can all skew results. If you don’t control for these, you might be crediting the test for something it didn’t cause.
What to do instead:
Track external events alongside your test. If a major campaign is running, acknowledge it in your analysis. And if you can, run the test again under normal conditions to validate your findings.
-
Skipping A/A Tests
Surprisingly, many companies don’t check if their testing tool works properly before running experiments. A/A tests (where you test identical versions against each other) help confirm that your tool is set up correctly.
Without this step, you might assume an A/B test is showing a difference when, in reality, it’s just faulty tracking. Imagine changing your site based on data that was never accurate in the first place.
Here’s the right move:
Every once in a while, run an A/A test to verify your setup. If your tool reports a big difference between identical versions, something’s bro
‘ken. Fix it before you start making data-driven decisions that aren’t actually data-driven.
Mistakes To Avoid After an A/B Test
Running an A/B test is just the first step. What happens after the test ends determines whether all that effort leads to meaningful improvements or just wasted data. Many companies drop the ball at this stage by misreading results, failing to document findings, or simply not acting on what they’ve learned.
-
Misinterpreting Test Results
Numbers don’t lie, but they can definitely be misleading if you don’t analyze them correctly. One of the most common pitfalls is assuming that a slight uplift in conversions means a breakthrough.
Did the sample size reach statistical significance? Was the lift consistent across all segments? Are there hidden factors influencing the results? If you don’t dig deeper, you might act on a fluke instead of a real pattern.
How to prevent this
Don’t just look at the final conversion rate. Analyze trends over time, segment results by audience type, and use confidence intervals to validate findings. If something looks too good (or too bad) to be true, double-check before rolling out changes sitewide.
-
Testing Irrelevant Elements
Not every element on your website is worth testing. Changing the color of a footer link might not do much for conversions, yet some teams still spend time on minor tweaks that don’t move the needle. The biggest mistake? Treating every test as equally valuable instead of prioritizing high-impact experiments.
A better approach
Focus on testing elements influencing user behavior—headlines, CTAs, pricing models, and checkout flows. Before running a test, ask: “If this wins, how much will it actually change?” If the answer is “not much,” move on to something that matters.
-
Copying Others’ Tests Without Adaptation
Just because an A/B test worked for another company doesn’t mean it will work for you. Businesses operate in different industries, serve different audiences, and have unique challenges. Blindly copying someone else’s test is like wearing their prescription glasses—there’s a high chance it won’t be the right fit.
What to do instead:
Use other tests as inspiration, but tailor them to fit your audience’s behavior and preferences. Adapt tests based on your unique context and objectives to ensure they are relevant and effective for your specific situation. Consider factors like customer behavior and industry trends to make informed adjustments.
-
Neglecting User Feedback
Ignoring qualitative user feedback can result in missing out on valuable insights that quantitative data alone can’t provide.
User feedback helps you understand the “why” behind user behaviors, revealing pain points and preferences that numbers might not show. Neglecting this feedback can lead to incomplete analyses and suboptimal changes.
The solution
Regularly collect user feedback through surveys, interviews, and usability tests. Integrate this qualitative data with your quantitative results to fully understand user experiences.
Use feedback to inform your test designs and identify areas for improvement that align with user needs and preferences.
-
Misinterpreting Test Results
Misinterpreting test results can lead to incorrect conclusions and poor decision-making. This often happens when statistical concepts are misunderstood or when the data is not analyzed correctly.
For example, assuming a minor difference in conversion rates is significant without proper analysis can mislead your strategy. Misinterpretations can result in implementing changes that don’t benefit your business.
How to Avoid
Use proper data analysis techniques and ensure you understand key statistical concepts. Consider seeking expert advice or conducting peer reviews to verify your interpretations.
Utilize visual aids like graphs and charts to help interpret data more accurately. Avoid changing parameters mid-test, which can lead to confusion and unreliable results.
-
Overestimating the Impact of Changes
Overestimating the impact of changes can lead to unrealistic expectations and disappointment when results don’t meet these inflated predictions.
It’s easy to assume that a positive test result will lead to substantial improvements, but the actual impact is often more modest. This can result in misallocated resources and focus on less effective strategies.
How to Avoid
Set realistic goals and validate changes through multiple tests before scaling. Measure progress incrementally and adjust expectations based on actual results. Ensure you consider a range of metrics to get a balanced view of the impact, not just focusing on the most optimistic ones.
-
Failing to Document and Learn from Tests
Failing to document your tests can lead to repeating mistakes and missing opportunities for improvement. Without proper documentation, it’s hard to track what was tested, why it was tested, and what the outcomes were.
This lack of record-keeping can hinder learning and prevent you from building on past insights, leading to inefficiencies and missed chances to optimize further.
How to Avoid
Create a testing log. Document the hypothesis, results, insights, and next steps for every experiment. Over time, this will become a knowledge base that helps you refine future tests and avoid wasted effort.
-
Not Iterating on Test Results
Not iterating on test results can result in missed opportunities for continuous improvement. A single A/B test is rarely enough to fully optimize an element or strategy. Without iteration, you might stop at the first sign of success without exploring further enhancements or addressing remaining issues.
How to keep improving:
Plan follow-up tests based on initial results to refine and improve your findings. Use an iterative approach to build on successful tests, continually optimizing for the best possible outcomes.
This method ensures you’re always progressing and fine-tuning your strategies for maximum effectiveness.
Conclusion
A/B testing can do wonders for your business when done right. However, as we’ve seen, small mistakes can throw off your results, waste time, and lead to decisions that don’t actually help.
Avoiding these pitfalls isn’t just about following best practices; it’s about making sure your tests give you insights you can trust.
The key to successful A/B testing isn’t just running experiments, it’s learning from them. Every test, whether it confirms your hypothesis or surprises you, helps you understand what works and what doesn’t. I’m that’s the real goal; making smarter, data-backed decisions that move your business forward.
Frequently Asked Questions on A/B Testing Mistakes
What type of data errors can you expect with A/B testing?
A/B testing can be affected by several data errors, including sampling errors (when the sample size isn’t representative of the full audience), tracking errors (if analytics tools fail to record user actions accurately), and external influence errors (seasonality, competitor actions, or marketing campaigns impacting results). Additionally, bot traffic or ad blockers can sometimes skew results by preventing data collection from a portion of users.
What are the flaws of A/B testing?
A/B testing has its limitations. It only tests one variable (or a small set of changes) at a time, which means it doesn’t capture holistic user behavior or long-term trends. It also requires significant traffic to achieve statistical significance, making it difficult for small businesses to run meaningful tests. Additionally, short-term wins from A/B tests don’t always translate to long-term improvements, as user behavior can change over time.
What are the limitations of A/B testing?
A/B testing focuses on comparing variations but doesn’t explain why users behave a certain way. It also doesn’t account for external factors like seasonal trends, market shifts, or user intent. Another limitation is that small traffic sites may struggle to reach statistical significance, making results less reliable. Finally, A/B tests require careful execution—incorrect sample sizes, stopping tests too early, or testing insignificant elements can lead to misleading conclusions.
What are Type 1 and Type 2 errors in A/B testing?
- Type 1 Error (False Positive): This occurs when you think a variation has a significant impact when, in reality, the observed difference is due to random chance. It leads to implementing ineffective changes based on misleading data.
- Type 2 Error (False Negative): This happens when you fail to detect a real difference between variations, meaning you might miss out on an improvement that could have helped conversions. This is often due to low sample size or ending a test too soon before statistical significance is reached.